七连发!阿里多款重磅发布亮相云栖大会
2025-09-24 16:51:07 世界浙商
世界浙商客户端讯(记者 姚恩育) 9月24日,2025云栖大会现场,阿里云CTO周靖人接连发布了七款大模型技术产品。七款技术产品覆盖语言、语音、视觉、多模态、代码等模型领域,在模型智能水平、Agent工具调用以及Coding能力、深度推理、多模态等方面均实现突破。

在大语言模型中,阿里通义旗舰模型Qwen3-Max全新亮相,性能超过GPT5、Claude Opus 4等,跻身全球前三。Qwen3-Max包括指令(Instruct)和推理(Thinking)两大版本,其预览版已在 Chatbot Arena 排行榜上位列第三,正式版性能可望再度实现突破。
Qwen3-Max是通义千问家族中最大、最强的基础模型,预训练数据量达36T,总参数超过万亿,拥有极强的Coding编程能力和Agent工具调用能力。在大模型用Coding解决真实世界问题的SWE-Bench Verified测试中,Instruct版本斩获69.6分,位列全球第一梯队;在聚焦Agent工具调用能力的Tau2-Bench测试中,Qwen3-Max取得突破性的74.8分,超过Claude Opus4和DeepSeek-V3.1。Qwen3-Max推理模型也展现出非凡性能,结合工具调用和并行推理技术,其推理能力创下新高,尤其在聚焦数学推理的AIME 25和HMMT测试中,均达到突破性的满分100分,为国内首次。
下一代基础模型架构Qwen3-Next及系列模型正式发布,模型总参数80B仅激活 3B ,性能即可媲美千问3旗舰版235B模型,实现模型计算效率的重大突破。Qwen3-Next针对大模型在上下文长度和总参数两方面不断扩展(Scaling)的未来趋势而设计,创新改进采用了混合注意力机制、高稀疏度 MoE 结构、多 token 预测(MTP)机制等核心技术,模型训练成本较密集模型Qwen3-32B大降超90%,长文本推理吞吐量提升10倍以上,为未来大模型的训练和推理的效率设立了全新标准。
在专项模型方面,千问编程模型Qwen3-Coder重磅升级。新的Qwen3-Coder与Qwen Code、Claude Code系统联合训练,应用效果显著提升,推理速度更快,代码安全性也显著提升。Qwen3-Coder此前就广受开发者和企业好评,代码生成和补全能力极强,可一键完成完整项目的部署和问题修复,开源后调用量曾在知名API调用平台OpenRouter上激增1474%,位列全球第二。
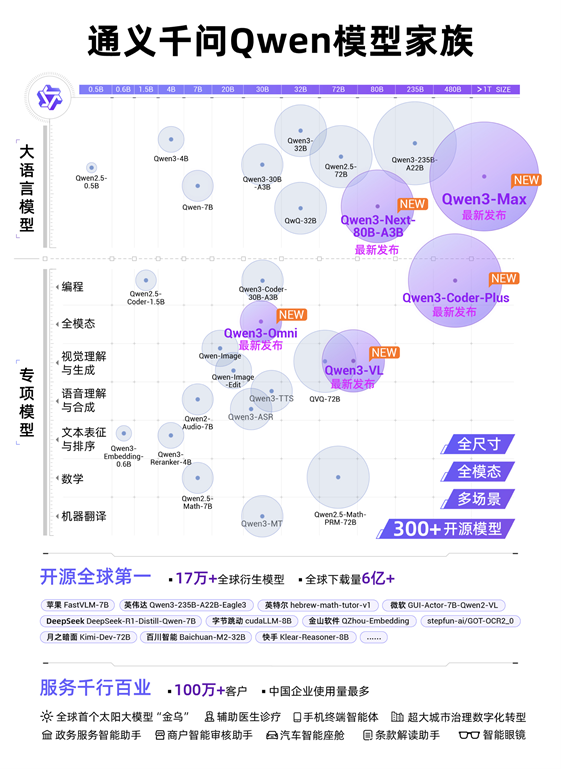
通义千问Qwen模型家族图
在多模态模型中,千问备受期待的视觉理解模型Qwen3-VL重磅开源,在视觉感知和多模态推理方面实现重大突破,在32项核心能力测评中超过Gemini2.5-Pro和GPT5。Qwen3-VL拥有极强的视觉智能体和视觉Coding能力,不仅能看懂图片,还能像人一样操作手机和电脑,自动完成许多日常任务。输入一张图片,Qwen3-VL可自行调用agent工具放大图片细节,通过更仔细的观察分析,推理出更好的答案;看到一张设计图,Qwen3-VL 就能生成Draw.io/HTML/CSS/JS 代码,“所见即所得”地完成视觉编程。此外,Qwen3-VL还升级了3D Grounding(3D检测)能力,为具身智能夯实基础;扩展支持百万tokens上下文,视频理解时长扩展到2小时以上。
全模态模型Qwen3-Omni惊喜亮相,音视频能力狂揽32项开源最佳性能SOTA,可像人类一样听说写,应用场景广泛,未来可部署于车载、智能眼镜和手机等。用户还可设定个性化角色、调整对话风格,打造专属的个人IP。类似于人类婴儿一出生就全方位感知世界,Qwen3-Omni一开始就加入了“听”、“说”、“写”多模态混合训练。在预训练过程中,Qwen3-Omni采用了混合单模态和跨模态数据。此前,模型在混合训练后,各个功能会相互掣肘甚至降智,比如音频理解能力提升,文字理解能力反而降低了。但Qwen3-Omni在实现强劲音频与音视频能力的同时,单模态文本与图像性能均保持稳定,这是业内首次实现这一训练效果。
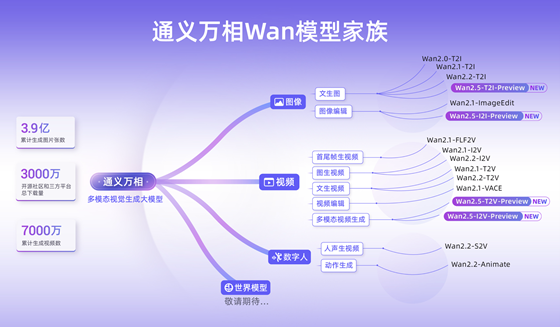
通义万相Wan模型家族图
通义万相是通义大模型家族中的视觉基础模型,此次推出Wan2.5-preview系列模型,涵盖文生视频、图生视频、文生图和图像编辑四大模型。通义万相2.5视频生成模型能生成和画面匹配的人声、音效和音乐BGM,首次实现音画同步的视频生成能力,进一步降低电影级视频创作的门槛。通义万相2.5视频生成时长从5秒提升至10秒,支持24帧每秒的1080P高清视频生成,并进一步提升模型指令遵循能力。此次,通义万相2.5还全面升级了图像生成能力,可生成中英文文字和图表,支持图像编辑功能,输入一句话即可完成P图。

阿里云CTO周靖人发布通义百聆
此次云栖大会上,通义大模型家族还迎来了全新的成员——语音大模型通义百聆。百聆新发布了语音识别大模型Fun-ASR和语音合成大模型Fun-CosyVoice。Fun-ASR基于数千万小时真实语音数据训练而成,具备强大的上下文理解能力与行业适应性;Fun-CosyVoice可提供上百种预制音色,可以用于客服、销售、直播电商、消费电子、有声书、儿童娱乐等场景。
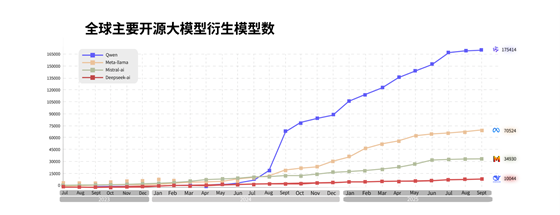
从0.5B到超万亿,包含三百个大模型的通义大模型家族覆盖“全尺寸”,囊括LLM、编程、图像、语音、视频等“全模态”,可满足从智能终端到云上的多场景需求。自2023年开源第一款模型以来,通义大模型在全球下载量突破6亿次,衍生模型突破17万个,已发展成为全球第一开源模型。除了惠及AI开发者,通义衍生模型的开发机构还覆盖海内外国知名企业,包括苹果、英伟达、微软、DeepSeek和字节跳动等。截至目前,通义大模型已服务超100万客户。沙利文报告显示,2025年上半年,在中国企业级大模型调用市场中,通义位列第一。